
The Four Stages of IoT - The Data Processing Stage
This is the third post in the series The Four Stages of IoT: A Data-Centric Taxonomy of the IoT
Previously, we discussed the connectivity stage, which explored how devices establish a connection with edge devices or the ecosystem backend. Today, we will go one layer deeper and focus on what we do with the data after establishing a reliable connection. I refer to this as the Data Processing Stage.
Data processing can happen in the back end or at the edge, and it involves performing work on the data such as filtering, transformations, enrichment, or analytics.
Types of Data Processing
Data Filtering deals with monitoring device data and accepting or rejecting the entire message or parts of it based on predefined criteria. For example, adding and removing fields from legacy payload formats to standardize them with newer formats
Data Transformations deals with transformation and manipulation tasks to standardize data and improve readability. For example, expanding the “C” in a temperature field’s unit to “Celsius”
Data Enrichment deals with adding contextual data to device messages. For example, appending a customer ID to the current message, based on the device ID.
Data Analytics deals with tasks such as deriving insights from the data in real time and interacting with Machine Learning models. This is perhaps the most critical component of a data-centric IoT architecture For example, deriving a Key Performance Indicator (KPI) based on IoT device data to understand equipment efficiency or executing a preventive maintenance Machine Learning model to address breakage before it happens.
Methods of Data Processing
Although data processing applications can live in physical servers, they are more common on edge computing devices or in the form of cloud-based Serverless Functions, Container Deployments, or Virtual Machines.
Edge Devices
Because of their powerful hardware, Edge devices can typically perform most types of data processing. It is common to see ML models hosted on the Edge device for immediate decision making about how it ought to manage local IoT Devices.
For example, an Edge Device could discard duplicate messages (filtering), attach building information before sending the message to the backend (enrichment), and using an ML model to alert local operators of a device in need of repair (analytics).
Virtual Machines and Servers
Data Processing applications can be hosted as a long-running job inside of virtual machines and servers. This approach is particularly useful when a specific stack not available in other compute platforms is required. For example, if you are required to use legacy applications running on legacy hardware or software, you might be limited to a server or virtual machine.
Containers
Container deployments remove much of the operational burden of maintaining a server, and with managed services like Google Cloud Run or AWS Fargate, it is also possible to only run the application when it is needed—such as when a device message is received.
Containers are preferable over Serverless Functions when large volumes of data need to be processed or when a specific software stack is not available on a Serverless Function platform.
For example, if you were ingesting tens-of-thousands of messages with software requiring disk access, Containers would be an optimal choice. That’s because they are easily scalable and configurable, and they are not tightly-coupled with any hardware platform nor operating system. However, this could have a slight added cost of operational management in the form of cluster configuration and container image management.
Serverless Functions
Serverless Functions provide the most hands-off experience in infrastructure management, and they are most apt for sporadic data processing. Writing a Serverless Function is as simple as selecting an environment, writing your application, and deploying it to the cloud.
Furthermore, cloud providers typically bill Functions per-execution, which can make the financial cost of data processing very close to 0 for low-volume workloads.
For example, imagine you have two developers assigned to build an application that processes incoming data for 1000 devices every second. Because the team is small, you want to avoid them as much of the infrastructure heavy-lifting as you can. Serverless Functions would achieve this by abstracting away most of the underlying infrastructure, and it would enable the pair to focus primarily on the code dealing with business and data processing logic. Moreover, the billing cost of running such a function would be roughly $0.30/month for processing data from all 1000 devices each second of the year!1
An Example Data Processing Application
The following diagram showcases an application which uses an AWS Lambda function to perform all the data processing activities discussed in this post:
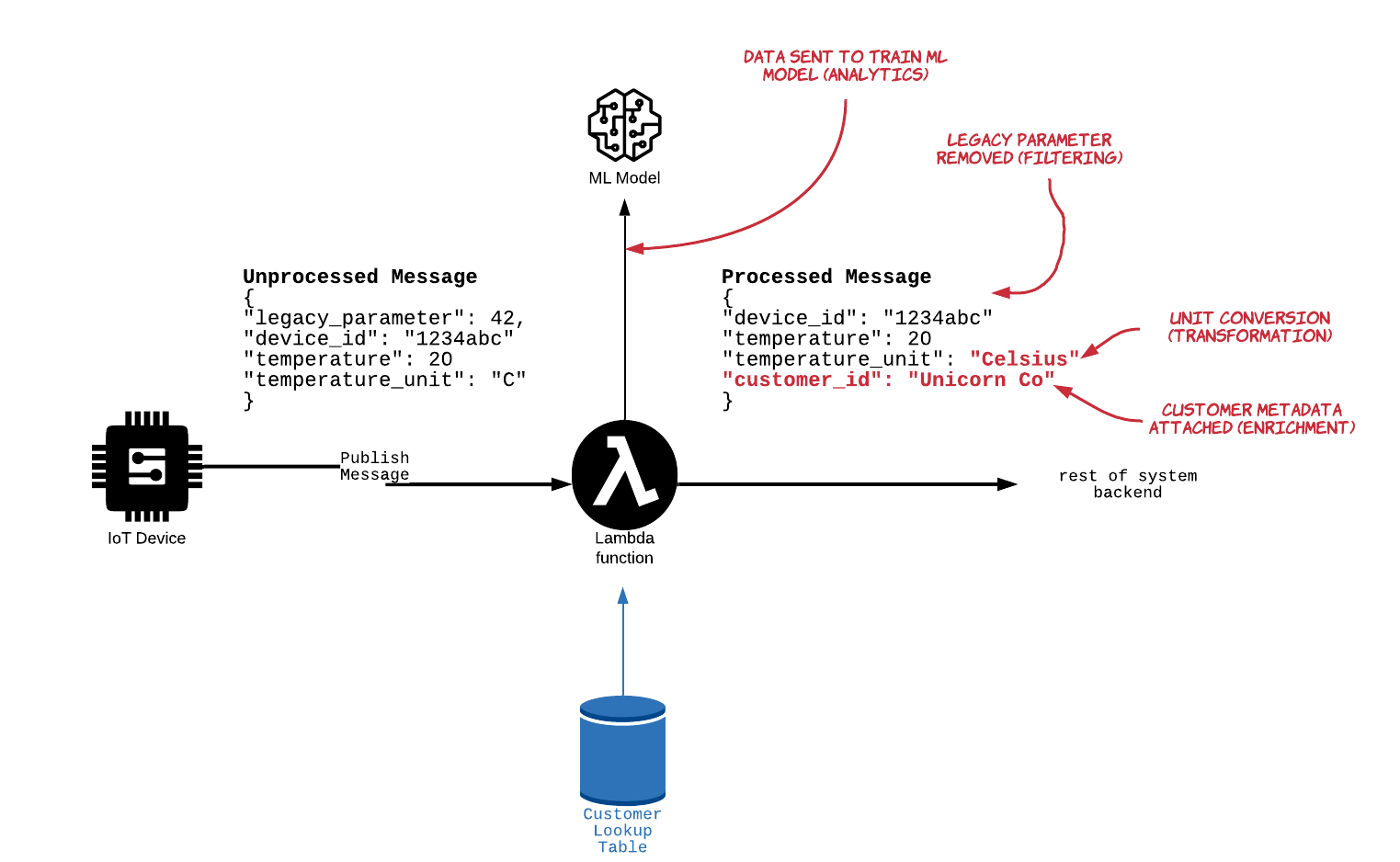
Conclusion
The Data Processing Stage provides the applications used to filter, transform, enrich, and analyze data from IoT devices. These applications can live on the Edge device, or server-side as Virtual Machines, container deployments, or serverless functions.
In the next post, we will explore the Data Storage stage, which consists of the file systems, databases, object stores, and “data lakes” that temporarily or permanently hold data about IoT ecosystems.
1 The assumption here is based on ~2.7 million executions of AWS Lambda using the following configuration: 128MB, 1 second executions, free tier included.