The Four Stages of IoT: A Data-Centric Taxonomy of the IoT
The Internet of Things (IoT) isn’t new. It is now a subject with a myriad of books written about it, new exciting college electives, and a generous assortment of products that have spectacularly succeeded or failed. As such, members of the tech community naturally have devised comprehensive, high-level taxonomies of IoT ecosystems.
These usually focus on smart devices and how they, when connected to a network or the Internet, can publish their data to a remote server or cloud provider. What happens to the data from there on is often reduced to a nondescript label of “data analytics.” However, the modern value of IoT is not merely remote data acquisition (we’ve had that for decades): it is the availability of insights about a massive amount of data over an extended time period.
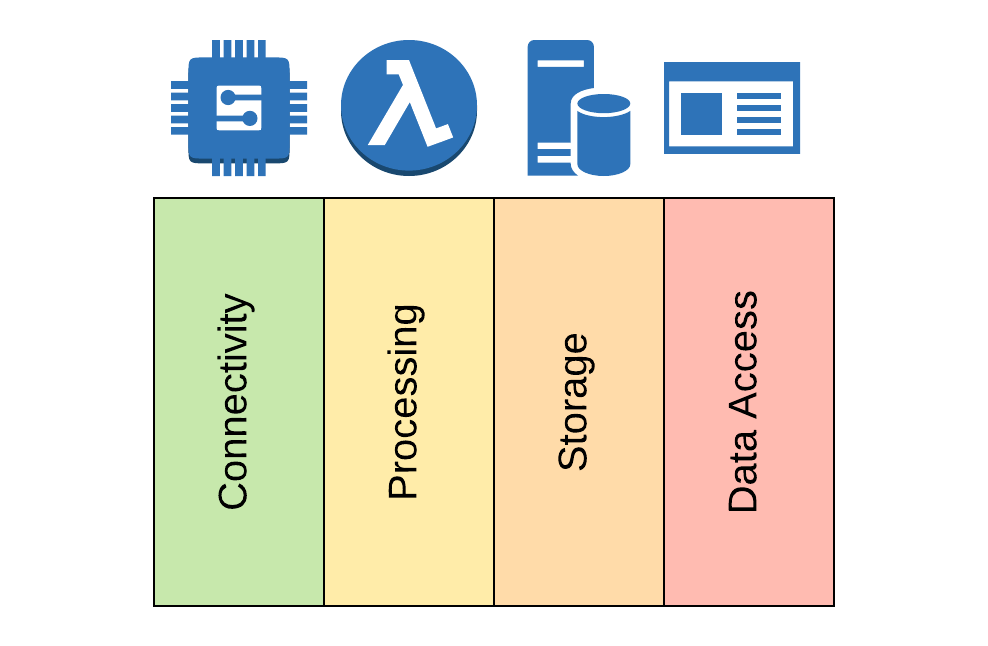
Because of that, in this blog series I’m titling “The Four Stages of IoT,” I will advocate for a data-centric taxonomy of the IoT. I will explore how edge and cloud computing are used in tandem today to extract large-scale, powerful, value-generating insights. With data as the epicenter, I will show you, through examples, how to dissect and understand an IoT ecosystem in four stages: connectivity, processing, storage, and access.